Recently, I needed to add a “Download all” button in a Rails application for managing meeting assets. Specifically, this magic button would allow attendees to download all the meeting documents in a single zip file. Before I explain how I tackled streaming of large zip files, let’s first look at the files storage implementation.
How the Files are Stored
Since Rails 5.2, there is a baked-in solution for handling file uploads named Active Storage. What I like about this is that it doesn’t require you to alter any of your application existing models with extra columns to support file uploads. You can easily add file uploading to any model in your application. Active Storage achieves this flexibility via a polymorphic association in the ActiveStorage::Attachment model, which is a join model between your record and the ActiveStorage::Blob model:
# rails/active_storage/app/models/active_storage/attachment.rb
class ActiveStorage::Attachment < ActiveRecord::Base
...
belongs_to :record, polymorphic: true, touch: true
belongs_to :blob, class_name: "ActiveStorage::Blob"
...
end
The ActiveStorage::Blob record contains all the necessary file metadata. Among them a unique key to the storage location, filename, content type, byte size and more. Later, we will use the Blob model to access our storage files content bit by bit.
Despite using the Active Storage, the advice in this article is storage agnostic. There are many other great alternatives for handling file uploads such as Carrierwave, Dragonfly or Shrine. But we’re going to stick with the default storage solution here.
We aren’t going to go cover setting up active storage from scratch. Please follow the official Rails guides on how to do it in your project. Instead, our starting point will be a Meeting model. The only thing we need to do to be able to attach many documents to our meeting is to use has_many_attached method:
# app/models/meeting.rb
class Meeting < ApplicationRecord
has_many_attached :documents
end
A Common Approach
The common solution to downloading zip archives is to create an entire zip file with all the files first. This means reading each file into memory first before writing it back to the disk as part of a single archived zip file. Once done, the web server will begin sending the zip file to the client.
Unfortunately, this approach has a few drawbacks. Depending on the sizes of files in the archive, you may need a lot of memory and disk space to generate a zip file. Even if you have ample resources, your application user may need to wait a long time before their browser starts downloading the archived file. The perceived lag and inactivity will negatively impact their experience.
So what’s the alternative?
Tricks Up the Streaming Sleeve
The solution is to stream a zip archive immediately to the client as the very first file is being read from the disk. This way, we don’t even have to wait for the file to be fully read. We can start streaming in smaller byte chunks without creating a zip file upfront. This approach removes the need for large disk space and reduces memory allocations as our zip content is sent over the wire in small chunks. With decreased latency and faster download time, the user experience improves significantly.
To stream large files in a single zip archive, we’re going to use the zip_tricks gem. The library boasts the ability to handle millions of zip files generated per day. So, we have our backs covered with the volume of archived files here as well.
Let’s add the download button.
The Download Button
We start by creating a request path that will handle streaming of our download. To do so, we add a download route to the meeting resources that will use a custom controller:
# config/routes.rb
resources :meetings do
member do
post :download, to: "zip_streaming#download"
end
end
It’s worth noting that we chose the POST method in place of GET. It’s so that we can skip having to deal with templates rendering in our controller action.
Next, we add a custom controller zip_streaming_controller.rb with a download action that will handle streaming of the zip archive:
# app/controllers/zip_streaming_controller.rb
class ZipStreamingController < ApplicationController
before_action :set_meeting
def download
end
private
def set_meeting
@meeting = Meeting.find(params[:id])
end
end
And finally, in our view, we add the “Download all” button that will trigger zip file download:
# app/views/meetings/show.html.erb
<%= button_to "Download all", download_meeting_path(@meeting), method: :post, data: { "no-turbolink" => true } %>
Now we’re ready to discuss the implementation of the download action.
File Download Response Headers
When discussing downloading files of any kind, we need to touch on the subject of HTTP response headers and, in particular, the Content-Disposition header. The Content-Disposition response header tells the browser how to display the response content. If the browser knows how to handle the MIME type, the inline value displays the content as part of the web page. Otherwise, the content is immediately downloaded. We can also instruct the browser to always download the content and save it locally. To do this, we use an attachment disposition. When the “Save as” dialog is presented, by default, the filename is the last segment of the URL. To change this, we can use filename attribute to name the downloaded file:
response.headers["Content-Disposition"] = "attachment; filename=\"download.zip\""
We also want to inform the browser about the content type. To do so we use the Content-Type response header with the “application/zip” MIME type:
response.headers["Content-Type"] = "application/zip"
To help the user identify their download, we name our archived file by the meeting title using an easy to read slug identifier. Putting it all together, we add the Content-Disposition and Content-Type response headers to the download action:
def download
zipname = "#{@meeting.slug}.zip".gsub('"', '\"') # escape quotes
disposition = "attachment; filename=\"#{zipname}\""
response.headers["Content-Disposition"] = disposition
response.headers["Content-Type"] = "application/zip"
end
There are many quirks when dealing with the filename attribute of a Content-Disposition header. For starters, the filename may contain special characters that need escaping. To handle the edge cases in filenames and make the solution more robust, we can use ActionDispatch::HTTP::ContentDisposition and the format method:
def download
zipname = "#{@meeting.slug}.zip"
disposition = ActionDispatch::Http::ContentDisposition.format(disposition: "attachment", filename: zipname)
response.headers["Content-Disposition"] = disposition
response.headers["Content-Type"] = "application/zip"
end
However, we’re not done with the response headers yet. Since we’re dealing with streaming, we do not know the byte length of our content. When the Content-Length header is omitted, the browser will assume that the content will be streamed in chunks in a single request/response cycle. So we ensure that the header is removed:
response.delete_header("Content-Length")
If our meeting app becomes widely successful, we want to be kind to our server resources and send a cached copy when possible. To control cache settings, we use the Cache-Control header with “no-cache” directive. Contrary to popular belief, the “no-cache” doesn’t imply that the server will perform no caching. It means that the server will perform validation before releasing a cached copy.
response.headers["Cache-Control"] = "no-cache"
For the server to perform cache validation, we need to provide a validator in our response as well. One choice is to use Last-Modified response header to validate the cached archive file. We use the Time class httpdate method to provide the date and time in the expected format for when the archive was last modified:
response.headers["Last-Modified"] = Time.now.httpdate.to_s
Before we finish headers declaration, we need to deal with the HTTP server buffering problem. Web servers like Nginx perform buffering to reduce overhead with writing and reading streamed content. The problem is that if you stream chunks of content, the Nginx’s will store them in a buffer and send it back to the client only when the buffer fills up or the stream closes. Unfortunately, this will make the browser wait for content. To disable this behaviour, we can use the X-Accel-Buffering header to stop the Nginx from buffering:
response.headers["X-Accel-Buffering"] = "no"
Finally, the download action with all the response headers looks like this:
def download
zipname = "#{@meeting.slug}.zip"
disposition = ActionDispatch::Http::ContentDisposition.format(disposition: "attachment", filename: zipname)
response.headers["Content-Disposition"] = disposition
response.headers["Content-Type"] = "application/zip"
response.headers.delete("Content-Length")
response.headers["Cache-Control"] = "no-cache"
response.headers["Last-Modified"] = Time.now.httpdate.to_s
response.headers["X-Accel-Buffering"] = "no"
end
Streaming the Zip File
Now, we can turn our attention to actually streaming the zip file content. To do this, we use the ZipTricks::BlockWriter that will be responsible for streaming chunks of the zip archive back to the browser. Each time a writer receives a chunk of content, it will call a block and write the content directly onto the response stream:
def download
...
writer = ZipTricks::BlockWrite.new do |chunk|
response.stream.write(chunk)
end
end
Having specified our writer, we’re ready to open a stream for writing. We use ZipTricks::Streamer and call the open method with a previously created writer to begin writing the zip archive. As we do so, we ensure that we close the stream when the streaming is done, otherwise the socket could be left open forever:
def download
...
writer = ZipTricks::BlockWrite.new do |chunk|
response.stream.write(chunk)
end
ZipTricks::Streamer.open(writer) do |zip|
end
ensure
response.stream.close
end
Next, one by one, we begin to retrieve meeting documents for streaming. We use the write_deflated_file method to create an entry in the zip archive. This method takes the document filename as an argument and yields back the previously created writer IO object that will serve for writing the document content:
def download
...
ZipTricks::Streamer.open(writer) do |zip|
@meeting.documents.each do |doc|
zip.write_deflated_file(doc.filename.to_s) do |file_writer|
...
end
end
end
ensure
response.stream.close
end
Thanks to ActiveStorage::Attachment association, we can access document metadata via the blob record. The ActiveStorage::Blob provides a download method which, when called with a block, will stream the file content in chunks. Be careful here though, as calling this method without a block would read the entire file into memory before returning its content - not what we want. Notice, since the file writer is an IO object it responds to the << message that we can use to write our chunks:
def download
...
writer = ZipTricks::BlockWrite.new do |chunk|
response.stream.write(chunk)
end
ZipTricks::Streamer.open(writer) do |zip|
@meeting.documents.each do |doc|
zip.write_deflated_file(doc.filename.to_s) do |file_writer|
doc.blob.download do |chunk|
file_writer << chunk
end
end
end
end
ensure
response.stream.close
end
The Missing Piece
Unfortunately, calling response.stream.write isn’t enough to make file streaming work. If you were to try running our code now, it would work but hold the browser from downloading until the full archived file is ready. Each chunk from the response.stream object would be added to the response buffer and sent to the client when the entire response body finishes.
There is one more piece missing from this puzzle - the ActionController::Live module. To make all your actions capable of streaming live data, all you need to do is to mix in this module into your controller:
# app/controllers/zip_streaming_controller.rb
class ZipStreamingController < ApplicationController
include ActionController::Live
...
end
Once the ActionController::Live is included, the response.stream.write will stream data to the client in real-time without buffering. When downloading you will see archive file size growing as in this example:
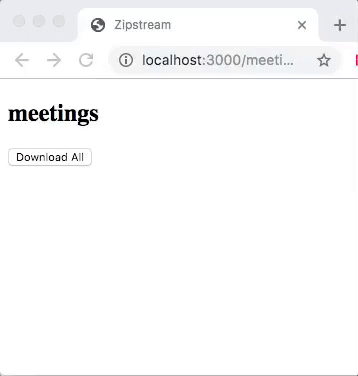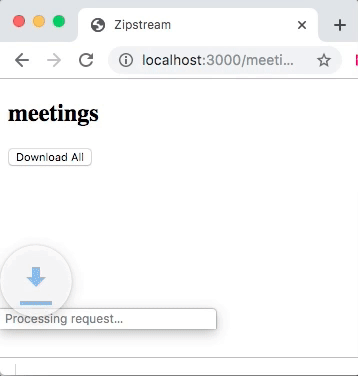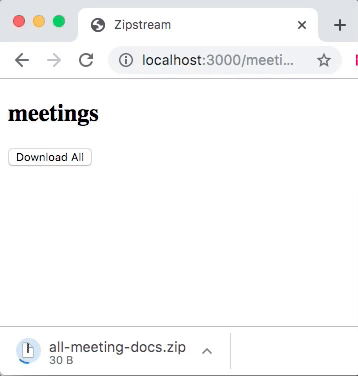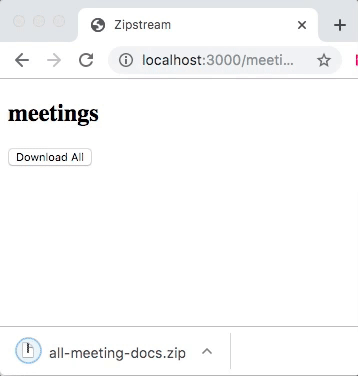
Under the covers, the streaming is done by executing an action in a child thread. This lets Rails, and specifically Rack process response body in parallel with sending data to the client. Because of this, you need to make sure your action is thread-safe. It also means that a web server needs to be capable of multithreading and streaming. But, Rails default web server Puma has you covered here. The final caveat is that you need to specify response headers before writing data to the response stream.
Summing it all up, the entire zip streaming controller with download action looks like this:
# app/controllers/zip_streaming_controller.rb
class ZipStreamingController < ApplicationController
include ActionController::Live
before_action :set_meeting
def download
zipname = "#{@meeting.slug}.zip"
disposition = ActionDispatch::Http::ContentDisposition.format(disposition: "attachment", filename: zipname)
response.headers["Content-Disposition"] = disposition
response.headers["Content-Type"] = "application/zip"
response.headers.delete("Content-Length")
response.headers["Cache-Control"] = "no-cache"
response.headers["Last-Modified"] = Time.now.httpdate.to_s
response.headers["X-Accel-Buffering"] = "no"
writer = ZipTricks::BlockWrite.new do |chunk|
response.stream.write(chunk)
end
ZipTricks::Streamer.open(writer) do |zip|
@meeting.documents.each do |doc|
zip.write_deflated_file(doc.filename.to_s) do |file_writer|
doc.blob.download do |chunk|
file_writer << chunk
end
end
end
end
ensure
response.stream.close
end
private
def set_meeting
@meeting = Meeting.find(params[:id])
end
end
Improving the Design
Even though we have a working implementation, there is still room for improvement. Apart from the method being verbose, it’s usually a bad practice to have so much code logic in a single controller action. Let’s do something about it.
We will deal with the headers first. As it turns out Rails provides a convenient method send_file_headers! for specifying the Content-Disposition and Content-Type headers. This method will ensure the right format and escaping for the file attachment. This will reduce the header specification to this:
def download
zipname = "#{@meeting.slug}.zip"
send_file_headers!(
type: "application/zip",
disposition: "attachment",
filename: zipname
)
response.delete_header("Content-Length")
response.headers["Cache-Control"] = "no-cache"
response.headers["Last-Modified"] = Time.now.httpdate.to_s
response.headers["X-Accel-Buffering"] = "no"
...
end
However, we can cut down the above response headers setup even further. The ActionController::Live module response.stream.write method deletes the Content-Length and sets the Cache-Control to “no-cache” headers for us, so we can remove them as well:
def download
zipname = "#{@meeting.slug}.zip"
send_file_headers!(
type: "application/zip",
disposition: "attachment",
filename: zipname
)
response.headers["Last-Modified"] = Time.now.httpdate.to_s
response.headers["X-Accel-Buffering"] = "no"
...
end
Next, we extract the streaming behaviour into a separate class called DocumentsStreamer. In the constructor, it will accept documents collection and allow us to enumerate over all the streamed chunks with each method. Essentially, turning our class into an Enumerable object. As a convenience, we add a class level method stream to abstract the underlying plumbing and provide a verb that expresses the class purpose.
# app/services/documents_streamer.rb
class DocumentsStreamer
include Enumerable
def self.stream(documents, &chunks)
streamer = new(documents)
streamer.each(&chunks)
end
attr_reader :documents
def initialize(documents)
@documents = documents
end
def each(&chunks)
writer = ZipTricks::BlockWrite.new(&chunks)
ZipTricks::Streamer.open(writer) do |zip|
documents.each do |doc|
zip.write_deflated_file(doc.filename.to_s) do |file_writer|
doc.blob.download do |chunk|
file_writer << chunk
end
end
end
end
end
end
Using the DocumentsStreamer, we can reduce our download action code down to this:
def download
...
DocumentsStreamer.stream(@meeting.documents) do |chunk|
response.stream.write(chunk)
end
ensure
response.stream.close
end
In the end, our refactored action uses Rails to its full potential and tells a more succinct story of how the download works:
def download
zipname = "#{@meeting.slug}.zip"
send_file_headers!(
type: "application/zip",
disposition: "attachment",
filename: zipname
)
response.headers["Last-Modified"] = Time.now.httpdate.to_s
response.headers["X-Accel-Buffering"] = "no"
DocumentsStreamer.stream(@meeting.documents) do |chunk|
response.stream.write(chunk)
end
ensure
response.stream.close
end
Summary
This concludes our overview of streaming large zip files in Rails. We covered a lot of ground by lifting the lid on how Active Storage can facilitate streaming of files. We explored various types of HTTP response headers that instruct clients to download content. All this wouldn’t be possible without a great zip_tricks gem and convenient Rails APIs. We finished by cleaning our code up and abstracting away the streaming, thus making the whole thing more maintainable.
I hope this was a useful article that showcased how you can implement any type of download feature and take advantage of Rails streaming API. Feel free to post a comment on social media.